
「業務を効率化したい!」と思っても、非ITエンジニアにとっては0からプログラミングするのは中々大変です。
確かに検索すれば情報は出てきますが、こんな壁に当たったことはないでしょうか。
- 基本的な使い方は検索したら出てきたけど自分のデータに応用できない
- フォルダ構成がネットの情報と異なり上手く走ってくれない
- エラーで調べてみても対処法が分からない
本記事では実際に非エンジニアの方が効率化したいと思った事例を使い、つまずきポイントとこれに対する現役エンジニア(私)のアプローチ方法をご紹介します。
タイトルにある通り、使用言語は「Python」操作対象ファイルは「CSV」です。
具体的なソースコードも記載していますので、ぜひご自身の業務向けにカスタマイズしてみてください!
やりたいこと
まずは何をやるのかをご説明します。
ファイルの中身について
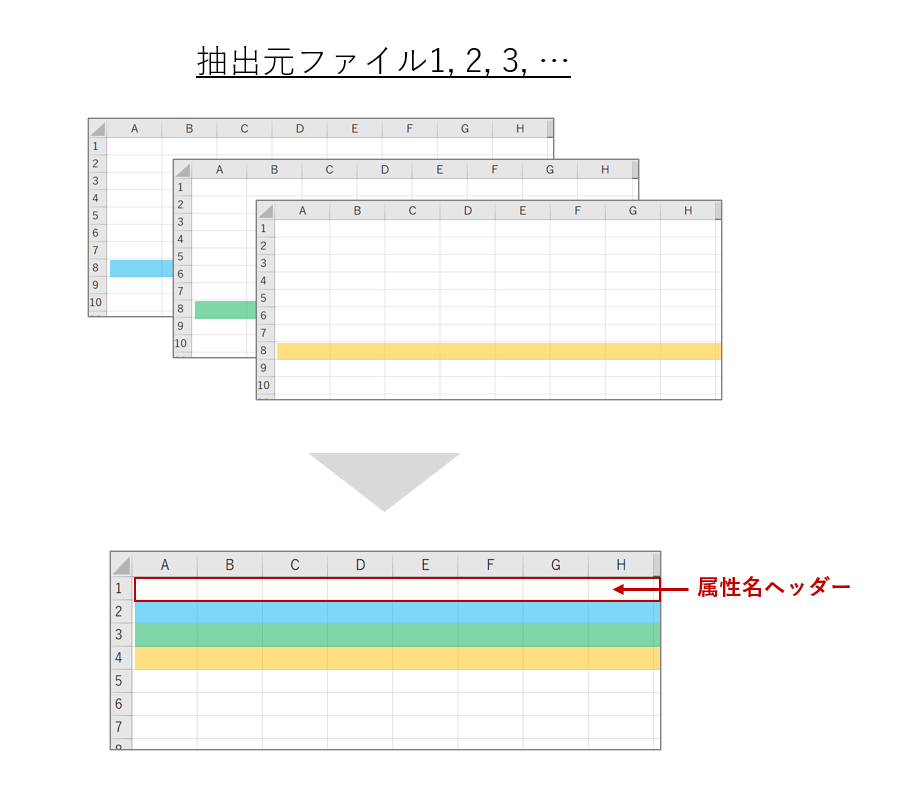
今回やりたいのは「特定の途中の行1つを取り出してまとめる」です。
イメージはこんな感じです。

「CSV Python 行抽出」なんて検索して出てくるのは「先頭を取り出します!」とか、「先頭からいくつ取り出します!」とかが多いですよね。
あとはヘッダーありなしとか、列指定とか、読み書きばかり。。。
ダメなんです。今回やりたいことは「先頭から〇行目の列だけ取り出す」なんです。
そして一つのCSVにまとめます。
フォルダ構成について
効率化したいと思うのって、ファイルがたくさんあって同じ動作を繰り返すことだと思います。
ただ、関数名や操作内容で検索して出てくる情報のほとんどは対象ファイルが1つな気がします。
本記事の対象は非ITエンジニアなので、このフォルダ構成だったらこうやる手はどう?と提案させていただきます。
今回は「data」というフォルダに抽出元のcsvファイルを20個置いてます。
「data」のフォルダと同じフォルダに今回の記事で作るPythonファイルがあります。

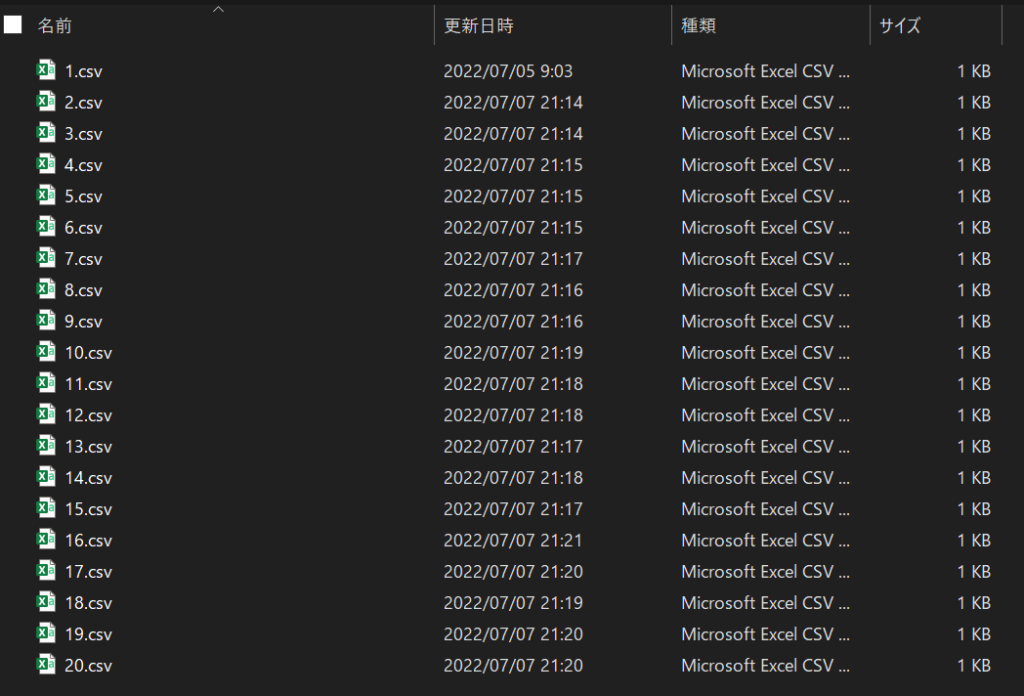
同じフォルダにあることを「同じ階層にある」と言ったり、さらに内側のフォルダにあることを「下の階層にある」と言ったりします。
今回の例ではプログラムから見てdataフォルダは同じ階層、csvファイルたちは下の階層にいます。
少し馴染みがないかもしれませんが解説でもよく出てくるので慣れておくと良いです◎
CSVファイルを読み込む
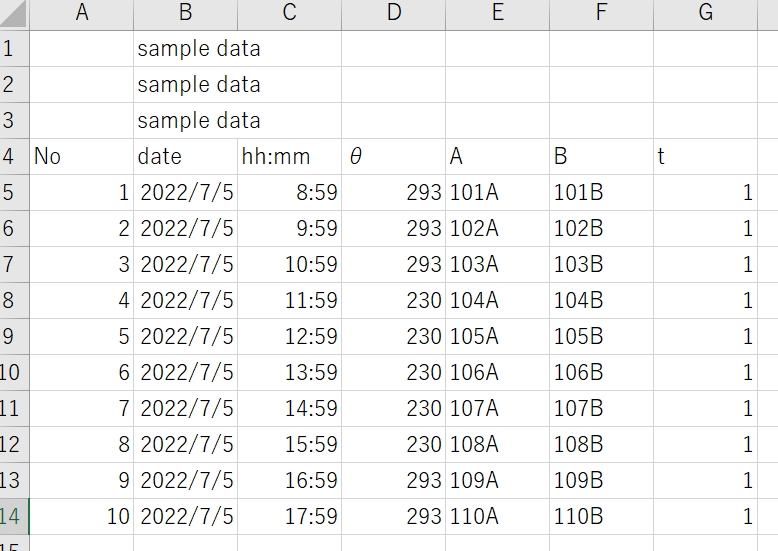
下記のサンプルのCSVファイルを読んでみます。
import pandas as pd
read_file = pd.read_csv("./data/1.csv")これだと下記のエラーが出ます。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 71: invalid start byte原因は「θ」です。他にも平仮名や漢字が入っているとNGです。
まずはこのエラーを対処しましょう。
使用オプション①「encoding」
対処と言ってもオプションを一つ指定するだけです。
「encoding」は他の形式のに変換するよ~という意味で、shift-jisを指定してあげれば読み込むことができます。
import pandas as pd
read_file = pd.read_csv("./data/1.csv",encoding = "shift-jis")
print(read_file)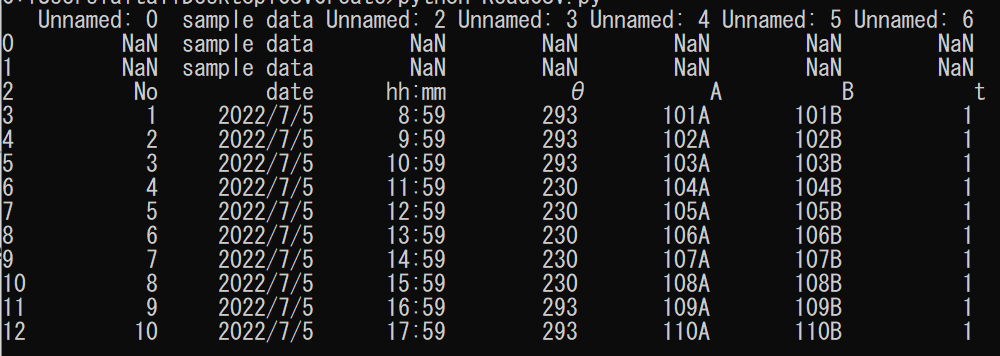
read_csv()は特に何も指定しないと「UTF-8」という文字コードで読み込んでしまうので、こちらから指定します。融通の効かないやつです。
非エンジニアの方は文字コードは存在を知っていれば十分ですが、未経験からエンジニアを目指している方であれば仕組みや概要は把握しておくと良いと思います。
使用オプション②「skiprows」
次は最初の方のいらないデータは読み込まないように工夫してみます。
今度もオプションを駆使するだけで簡単に実装できます。
skiprowsには数字またはリストを渡すことができます。
プログラムに馴染みがないとピンとこないですね。
それぞれの動きを見てみましょう。
数字を使った場合
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=1)
print(read_file)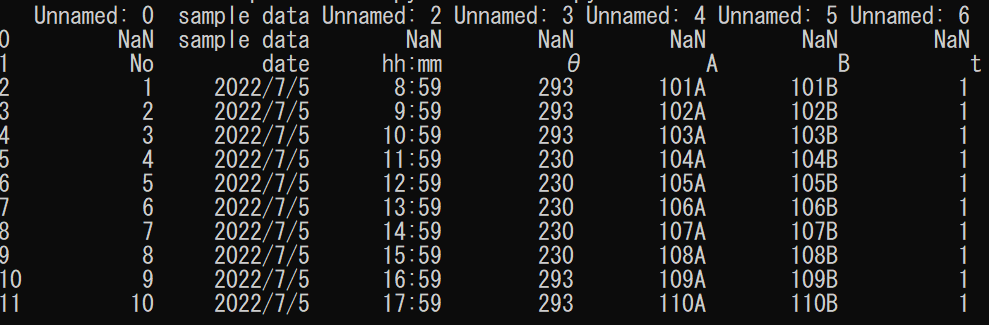
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=5)
print(read_file)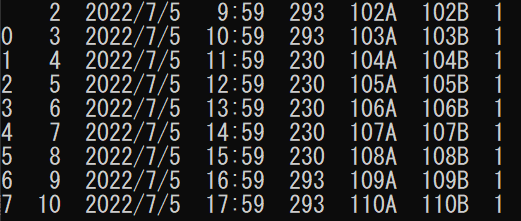
読み出し元のCSVファイルと比較してみると、skiprowsに設定した数だけ飛ばして読み込んでいることが分かります。
リストを使った場合
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=[1,2,3])
print(read_file)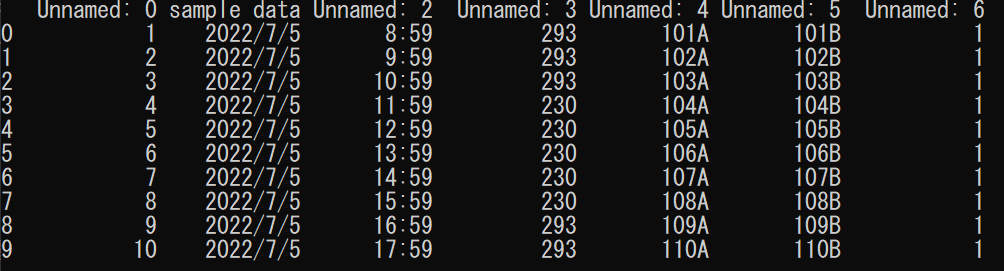
注意点は一番上の行(Excel画面だと1行目)をリストの指定では[0]とする点です。
混乱してきたらprint文で確認しながら進めてください。
リストの利点としてこのような指定も可能となります。
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=[0,1,2,3,5,7,9,11,13])
print(read_file)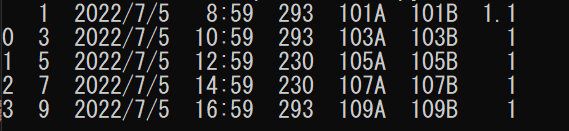
例だと2時間間隔でデータがとれていることになります。
ちなみに右上が「1.1」になってしまっているのはここをヘッダーだとみなされているからです。
一番左の「1」と被ってしまいます。
使用オプション③「nrows」
何行読み込むかを数字で指定します。
今回は1行だけ読み込みたいので「1」を指定します。お昼の時間の行を読み込んでみます。
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=6, nrows=1)
print(read_file)
おやおや。2行表示されていますね..?
違うんです。ヘッダーと1行が表示されているんです。
お気づきの方もいらっしゃると思いますが、一番左に元のCSVファイルには無い謎の連番がありますね。
これが読み込んだ時の行番号になります。
ということは、プログラムがヘッダーだと思っている部分はいらないよ!という指示を出せばOKです。
使用オプション④「header」
read_file = pd.read_csv("./data/1.csv",encoding="shift-jis", skiprows=6, nrows=1, header=None)
print(read_file)
これで特定の行だけを抽出し、それを囲むものはプログラムが自動で生成したヘッダー(0~6)と行番号だけになりました。
ファイルを全部読み込んで出力用のデータフレームを作る
まずは読み込んでみましょう。
globを使って対象ファイルリストを取得
ファイルが一つだけならわざわざプログラムを書くまでもありません。
dataフォルダの中のファイル全部に対して同じことを順番にやってみます。
globの他にos.walkを使用する方法もありますが、globの方がシンプルで情報も多く載っているようなので、今回はglobを使います。
「情報が多い=自分がやりたい処理に簡単にアクセスできる」ので非エンジニアほど多くの人が多方面から解説アプローチをかけているライブラリの使用をオススメします。
本記事ではglobは脇役なので簡単に流します。
正規表現を使いdataフォルダ内のcsvファイルをすべて取得します。
import glob
read_files = glob.glob("./data/*.csv")
for temp in read_files:
print(temp)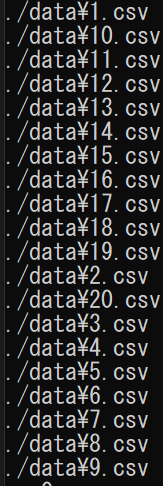
20個取れているようですね。
※4,5行目のコードは見やすくprintするためのものなので深く考えないでください。
ただ順番がイケてないですね。
データの順番がおかしくなってしまっては意味がないので対応します。
natsortedを使って並び替える
実は便利な関数があるんです。百聞は一見に如かず。見比べてください。
import glob
from natsort import natsorted
read_files = glob.glob("./data/*.csv")
sorted_files = natsorted(read_files)
for temp in sorted_files:
print(temp)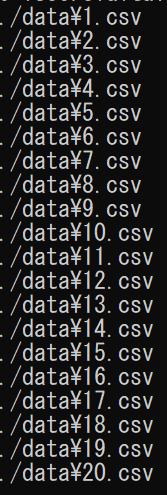
データフレームを読み込む
ファイルを一つ一つ読み込んで、大きな入れ物(リスト)に一つ一つ入れていくイメージです。
read_csv()で読み込まれると「データフレーム」という種類(型)として読み込まれるのですが、リストという種類に変換してデータを集めて、出力するときにもう一度「データフレーム」に戻します。
なぜこんな面倒な処理をするかというと、リストの操作に関する情報がネット上にたくさんあるからです。
この記事をベースに非エンジニアの方、未経験で勉強中の方がネットの情報を駆使して自力で自分のデータ形式に最適なコードを作れるようになれるといいな~と思って書いてます。
import pandas as pd
import glob
from natsort import natsorted
read_files = glob.glob("./data/*.csv")
sorted_files = natsorted(read_files)
for input_file in sorted_files:
# 特定の行のデータフレームを読み込む
input_df = pd.read_csv(input_file, encoding="shift-jis", skiprows=6, nrows=1, header=None)
# 種類の変換:データフレームからリストへ
input_list = input_df.to_numpy().tolist()
print(input_list)8行目でfor文を使ってファイルを一つ一つに対して処理を繰り返すようにします。
10行目でinput_dfという変数にデータフレームとして対象のデータを入れています。
13行目でinput_listとしてリスト形式に変換しています。
これでリストの形にはなるのですが2重構造になってしまいます。

内側の[]は1行を示していて、外側の[]は1データフレームを示しています。
このままだと「1行ずつ取り出す」ではなく、「1行の情報を持つデータフレームを取り出す」ことになってしまうので、一つ分リストを外します。
リストの平坦化を行う
プログラミングっぽく言うと多次元リストの平坦化を行います。
リストの中にリストがあることを多次元リストと言い、これを一次元のリストにすることを平坦化と言います。
本筋からずれるので詳しく説明しませんが、他の方法が気になる人は上記に挙げたキーワードで調べてみてください。
import pandas as pd
import glob
from natsort import natsorted
import itertools
read_files = glob.glob("./data/*.csv")
sorted_files = natsorted(read_files)
for input_file in sorted_files:
# 特定の行のデータフレームを読み込む
input_df = pd.read_csv(input_file, encoding="shift-jis", skiprows=6, nrows=1, header=None)
# 種類の変換:データフレームからリストへ
input_list = input_df.to_numpy().tolist()
# リストの平坦化
output_row = list(itertools.chain.from_iterable(input_list))
print(output_row)出力結果をみるとちゃんと[]が一つずつになっています。

リストをリストに追加する
データフレームの情報(2次元リスト)から行の情報(1次元リスト)を取り出せたので、データフレーム用の情報(2次元リスト)に作り替えていきます。
import pandas as pd
import glob
from natsort import natsorted
import itertools
read_files = glob.glob("./data/*.csv")
sorted_files = natsorted(read_files)
# 出力用に読み込んだ情報を入れていくリスト
output_list = []
for input_file in sorted_files:
# 特定の行のデータフレームを読み込む
input_df = pd.read_csv(input_file, encoding="shift-jis", skiprows=6, nrows=1, header=None)
# 種類の変換:データフレームからリストへ
input_list = input_df.to_numpy().tolist()
# リストの平坦化
output_row = list(itertools.chain.from_iterable(input_list))
# 行の情報を追加する
output_list.append(output_row)
print(output_list)10行目のoutput_listに20行目で作成したリストを23行目で追加しています。
25行目でのprint文はループが全部終わったら(全部の行を追加したら)表示してねという意図でfor文の外に書いています。
結果がこちら。

少し見にくいですが、20ファイル分の情報が入っています。
この時点ではリストの形式なので、データフレームに変換します。
二次元リストをデータフレームに変換する
これまで作成したのはデータの部分のみなので、ヘッダーを作成します。
元のファイルから読み込んでも良いのですが、今回は列数が少なかったので手打ちします。
今までの応用で元のファイルから読み込むこともできるので、気になった方はぜひチャレンジしてみてください!
import pandas as pd
import glob
from natsort import natsorted
import itertools
read_files = glob.glob("./data/*.csv")
sorted_files = natsorted(read_files)
# 出力用に読み込んだ情報を入れていくリスト
output_list = []
# 出力用ヘッダー
output_colums = ["No", "date", "hh:mm", "θ", "A", "B", "t"]
for input_file in sorted_files:
# 特定の行のデータフレームを読み込む
input_df = pd.read_csv(input_file, encoding="shift-jis", skiprows=6, nrows=1, header=None)
# 種類の変換:データフレームからリストへ
input_list = input_df.to_numpy().tolist()
# リストの平坦化
output_row = list(itertools.chain.from_iterable(input_list))
# 行の情報を追加する
output_list.append(output_row)
# データフレーム型に変換する
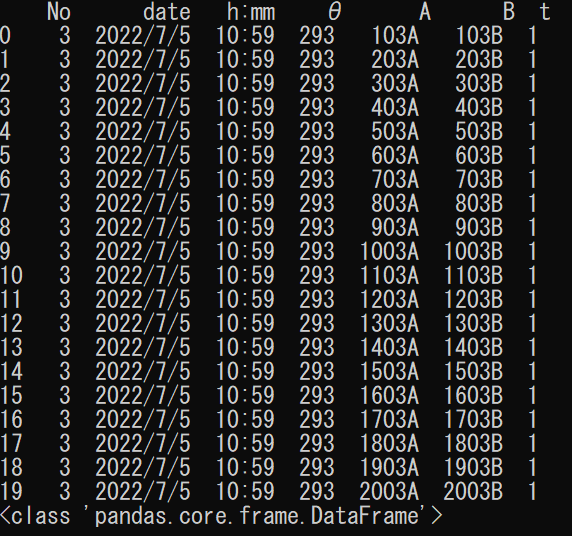
output_df = pd.DataFrame(output_list, columns=output_colums)
print(output_df)
print(type(output_df))type()を用い、ちゃんと型がデータフレームになっていることを確認します。
CSV出力
最後に出力してみましょう!
先ほどまでのコードに下記を追加するだけです。
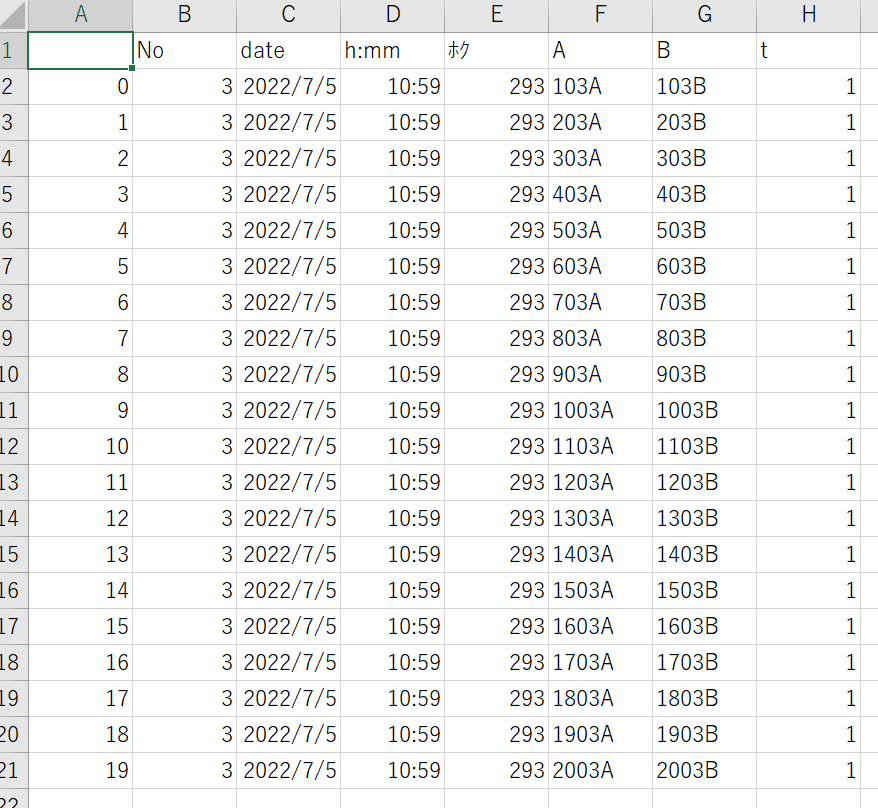
output_df.to_csv("sample.csv")おや?一番左(A列)にインデックス番号が付いてしまいました。
そしてθが「ホク」になってしまっていますね。
どちらもオプションで対応可能です!
使用オプション①「index」
一番左の正体は自動でつけてくれるインデックスです。
こちらから指定しないと親切に付けてくれてしまうので、いらないよー!というオプションをつけてあげます。
output_df.to_csv("sample.csv", index=False)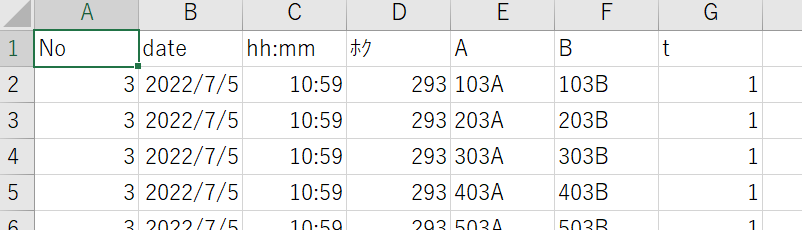
使用オプション②「encoding」
読み込みの時と同じく文字コードを指定してあげます。
output_df.to_csv("sample.csv", index=False, encoding="shift-jis")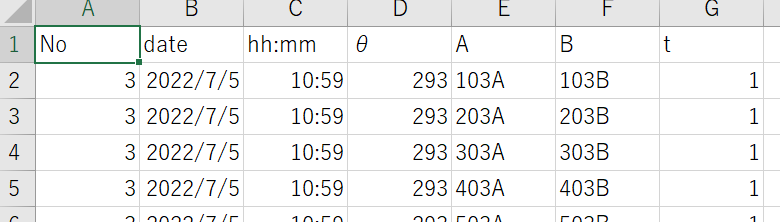
文字化けも治ってくれて完成です!
さいごに
お疲れさまでした。最後まで読んでくださりありがとうございます。
いかがでしたか。
ご自身の業務に合わせてカスタマイズできそうですか?
オプションは丸暗記する必要はないですが、こういうことできるな~という知見が貯まっていけばいくほど、ちょっとした業務を素早く自動化できると思います。
もし分からないことがあったらTwitterで質問してください。答えられる範囲でお助けします。


コメント